Splitting a string per the given seperator/delimiter similar to split() funtion in Python.
Implement with Knuth–Morris–Pratt string searching algorithm (or KMP algorithm) in C++ language.
★Source code here
Any feedbacks are welcome!
This task can be divide into two part. Firstly, we need to find out the position of matched delimiter in string. Secondly, we need to return a list of the words septerated by the delimiter considering special cases.
Pattern search
Although there are many methods(set 1-8) for pattern search, I focus on KMP algorithm which is clean and fast.
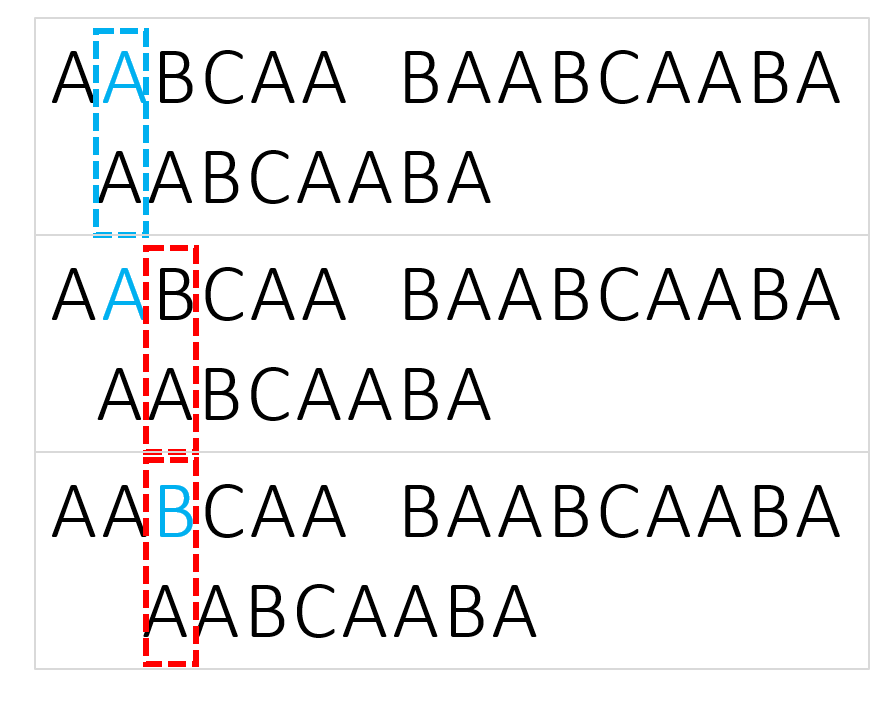
Example:
Search sep “AABCAABA” in string “AABCAA BAABCAABA”
Naive Pattern Searching
Well, my first thought was sliding the delimiter over string one by one for a match:
|
|
Notice: this function doesn’t split string by space in default. For example, split("a b c", "") = "a b c", which I think is also resonable.
Please read image from top to bottom, left to right.

Best case: First character of the delimiter is not present in string.split("AAAAAA", "BC")
Time complexity: O(m), m is string’s length.
Worst case: Only last character of the delimiter is different.split("AAAAAA", "AAB")
Time complexity: O((m-n+1)n), m is string’s length and n is delimiter’s length.
Knuth–Morris–Pratt(KMP) string searching algorithm
Time complexity: O(m+n) in worst case, m is string’s length and n is delimiter’s length.
In fact, we can directly jump to a potential position if the previous matched substring has same prefix and suffix. That is to say, we can make use of previous info and skip comparing some partial matched substring.
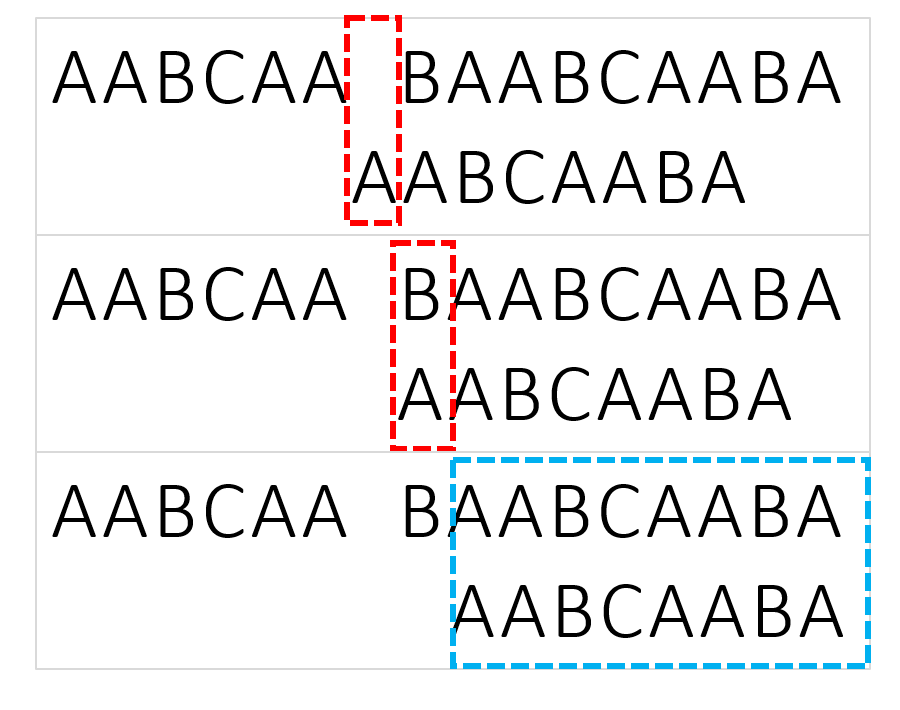
Please read image from top to bottom, left to right.
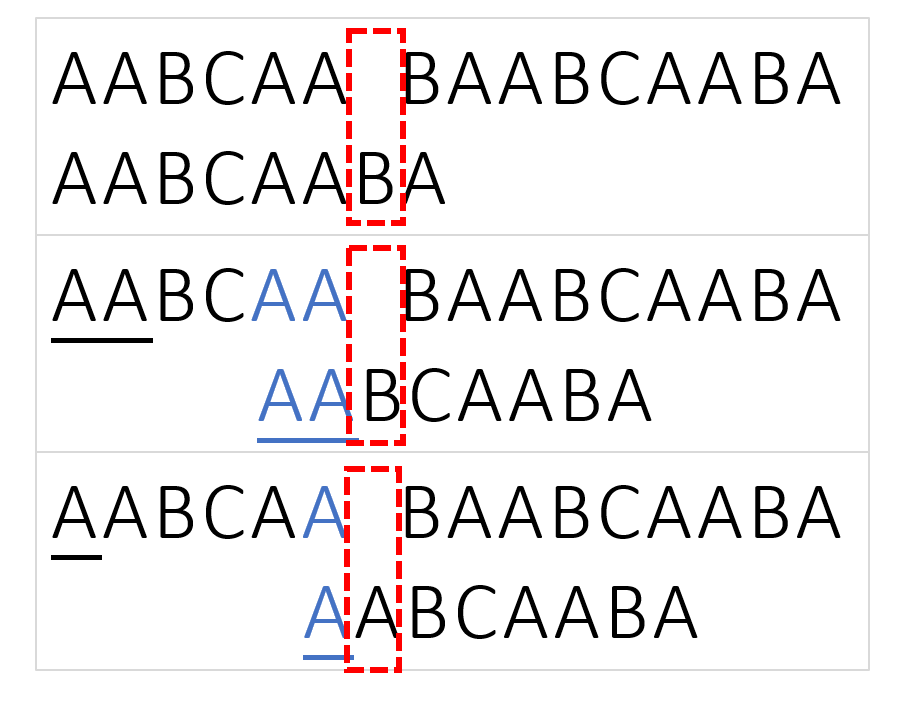
See also: this post(字符串匹配的KMP算法) provides explict diagrams too.
Then the only problem is how many steps we should jump? We should jump to the longest matched suffix:
|
|
|
|
For example, for delimiter AABCAABA, consider substring:AA: one character A matchedAAB: zero character matchedAABC: zero character matchedAABCA: one character A matchedAABCAA: two character AA matchedAABCAAB: three character AAB matchedAABCAABA: one character A matched
I recommend read codes by calculating the above example first.
|
|
Here’s my draft(L indicate len in code):
Matched prefix is the substring of [0, L] and suffix is the substring of [i-L, i]. They will become longer when matching (delimiter[i] == delimiter[len]), in which case i and L step forward simultaneously. If mismatch, L will step backward for a shorter potential matched string.
Their’s a trick when strings mismatch and L is not at the begining, we set len = res[len - 1]. Try to understand this trick by counterexample.

From the above codes, we can see their’s only one loop for each function, that’s why KMP has linear time complexity in worst case.
Split
We can find the split function definition in Python Standard Library
Return a list of the words in the string, using sep as the delimiter string.
If sep is given, consecutive delimiters are not grouped together and are deemed to delimit empty strings (for example, ‘1,,2’.split(‘,’) returns [‘1’, ‘’, ‘2’]). The sep argument may consist of multiple characters (for example, ‘1<>2<>3’.split(‘<>’) returns [‘1’, ‘2’, ‘3’]). Splitting an empty string with a specified separator returns [‘’].
If sep is not specified or is None, a different splitting algorithm is applied: runs of consecutive whitespace are regarded as a single separator, and the result will contain no empty strings at the start or end if the string has leading or trailing whitespace. Consequently, splitting an empty string or a string consisting of just whitespace with a None separator returns [].
Here I design various tests to consider as much categories as possible cases. All expected_outs are generated by python output. Some of the test cases come from Python documents.
|
|